
Le problème de la recherche de motifs dans les données est fondamental et a une longue et fructueuse histoire. Par exemple, les observations astronomiques approfondies de Tycho Brahe au XVIe siècle ont permis à Johannes Kepler de découvrir les lois empiriques du mouvement planétaire, qui à leur tour constituaient un tremplin pour le développement de la mécanique classique. De même, la découverte de régularités dans les spectres atomiques a joué un rôle clé dans le développement et la vérification de la physique quantique au début du XXe siècle. Le domaine de la reconnaissance de formes concerne la découverte automatique de régularités dans les données grâce à l’utilisation d’algorithmes informatiques et l’utilisation de ces régularités pour prendre des mesures telles que la classification des données en différentes catégories.
Prenons l’exemple de la reconnaissance des chiffres manuscrits, illustrée à la figure 1.1.
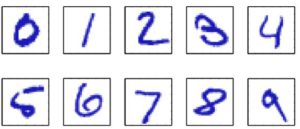
Chaque chiffre correspond à une image de 28 × 28 pixels et peut donc être représenté par un vecteur x comprenant 784 nombres réels. Le but est de construire une machine qui prendra un tel vecteur x en entrée et qui produira l’identité du chiffre 0, …, 9 en sortie. C’est un problème non négligeable en raison de la grande variabilité de l’écriture manuscrite. On pourrait y remédier en utilisant des règles ou des heuristiques artisanales pour distinguer les chiffres en fonction des formes des traits, mais en pratique, une telle approche entraîne une prolifération de règles et d’exceptions aux règles, et donne invariablement de mauvais résultats.
Des résultats bien meilleurs peuvent être obtenus en adoptant une approche d’apprentissage automatique dans laquelle un grand ensemble de N chiffres {$x_1$, …, $x_N$} appelé ensemble d’apprentissage est utilisé pour ajuster les paramètres d’un modèle adaptatif. Les catégories des chiffres de l’ensemble d’apprentissage sont connues à l’avance, généralement en les inspectant individuellement et en les étiquetant à la main. Nous pouvons exprimer la catégorie d’un chiffre en utilisant le vecteur cible t, qui représente l’identité du chiffre correspondant. Des techniques appropriées pour représenter des catégories en termes de vecteurs seront discutées plus tard. Notez qu’il existe un tel vecteur cible t pour chaque image numérique x.