
Ophir Frieder
Introduction
Les systèmes de recherche sont souvent considérés comme une «technologie mature» et, en effet, cette perception est correcte dans une certaine mesure. Par exemple, les utilisateurs d’ordinateurs s’appuient quotidiennement sur Google ™, Bing ™ et d’autres moteurs de recherche.
Ces moteurs de recherche Web sont faciles à utiliser, très fiables et gèrent des index, et donc des liens, vers des références potentielles à un large éventail de sujets. En outre, de nombreux moteurs de recherche d’informations matures sont disponibles pour rechercher des documents texte générés par ordinateur. Ces observations soutiennent la perception de la maturité; Le problème est qu’une grande partie des documents «monde réel» n’est ni indexée par les moteurs de recherche Web, ni disponible dans un format de texte lisible par ordinateur.
Les documents du «monde réel» sont en effet constitués de texte, mais ils incluent souvent de nombreux artefacts autres que du texte. Par exemple, les documents peuvent inclure des graphiques, des graphiques, des images, des signatures, des logos, des annotations manuscrites, des filigranes et des tampons. Il est clair que ces composants, comme le composant de texte, contiennent des informations pertinentes et que ces informations doivent être consultables.
Les moteurs de recherche actuels ignorent simplement ces autres types de composants.
Une autre caractéristique d’une grande partie des documents « monde réel » est que les documents ne sont pas lisibles par ordinateur. C’est-à-dire que ces documents sont souvent disponibles uniquement en format papier plutôt que dans un format électronique commun. Pour les fournir dans un format électronique, les documents sont scannés. Cependant, leur format d’image dérivé est souvent de qualité dégradée car les scanners introduisent un niveau de distorsion. En outre, ce processus suppose également que la copie papier est d’une qualité raisonnable pour commencer, ce qui est souvent une fausse supposition.
Dans le domaine juridique, souvent dans la «phase de découverte» du litige, le défendeur est tenu de produire tous les documents pertinents; ces documents sont souvent des graphiques imprimés, des notes manuscrites, des annotations sur du texte imprimé et des feuilles froissées de documents de conception. La numérisation de ces documents, en plus d’être coûteuse et longue, produit souvent des images de qualité médiocre qui sont relativement inutiles en termes de recherche même après les avoir traitées en utilisant un logiciel de reconnaissance optique de caractères (OCR).
La même situation existe dans le domaine du renseignement, du domaine des documents historiques, de l’arène médicale et de nombreux autres environnements. Même avec des techniques de restauration d’images déformées, telles que celles trouvées dans Agam et al. (2007), la qualité de l’image, et donc la précision de la reconnaissance des caractères, reste faible.
Pour soutenir la recherche de documents «réels», le Laboratoire de recherche d’information (IR) de l’Illinois Institute of Technology (IIT), collabore avec des chercheurs de l’Université d’État de New York à Buffalo (SUNYAB) et de l’Université du Maryland ( UMD) et les intégrateurs de systèmes de Clarabridge, Inc. ont développé, en moins d’un an, un prototype complexe de traitement de l’information documentaire (CDIP) (Argamon et al., 2006). Ce prototype, le premier du genre au mieux de nos connaissances, est basé sur l’intégration de plusieurs technologies matures (Chen et al 2005, Srihari et al 2004, 2006) travaillant à l’unisson pour améliorer significativement l’état de l’art. . Par cette intégration, les résultats préliminaires obtenus prouvent déjà le vieil adage selon lequel « le tout est plus grand que la somme de ses parties ».
Les parties dans le contexte du CDIP sont des technologies matures, à savoir la reconnaissance optique de caractères, l’extraction de tables, la reconnaissance de logos, la reconnaissance de mots manuscrits, l’appariement de signatures, la recherche d’informations, l’exploration de données, etc. ces «solutions ponctuelles» arrivent à maturité. Dans un proche avenir, nous prévoyons d’intégrer des fonctionnalités supplémentaires dans notre prototype. Cette fonctionnalité supplémentaire inclut potentiellement des versions commercialisées de solutions ponctuelles développées à l’origine dans le laboratoire IR de l’IIT telles que le Advanced Information Retrieval Engine – AIRE (sous licence IIT par Harris Corporation), le Arabic Stemmer (sous licence IIT par Blue Shoe Technologies) et le ITI Intranet Mediator (breveté par et autorisé sous licence IIT par Intranet Mediator, Inc).
AIRE est un moteur de recherche très précis, comme le montre l’évaluation industrielle indépendante réalisée par le personnel de Harris Corporation avant son octroi de licence (Infantes-Morris et al., 2003). Cependant, en raison des contraintes d’espace, nous renonçons à une discussion plus approfondie de l’AIRE. Pour un texte général couvrant les techniques de recherche et les optimisations telles que celles déployées dans AIRE, voir Grossman et Frieder (2004).
Traitement d’informations de document complexe
Comme indiqué précédemment, les documents complexes ou du «monde réel» sont généralement disponibles uniquement sur papier. En plus du texte écrit à la machine, ils comprennent souvent des logos, des notes manuscrites, des signatures et / ou des tableaux. Parfois, ils ont du texte dans plusieurs langues.
Sur la figure ci-dessous, nous voyons un document complexe relativement propre.
Cette image numérisée, qui fait partie de la collection de documents rendue publique par l’Accord-cadre sur le tabac (Lewis et al., 2006), comprend un texte imprimé, un logo délimité par un ovale en pointillé, une signature entourée d’un ovale timbre-délimité par un rectangle en pointillé. Comme on le voit, cette image numérisée est relativement propre en ce sens que le texte est de type écrit, clair, c’est-à-dire qu’il n’est pas déformé et, pour la plupart, chaque composant est séparé, à savoir qu’il n’y a pas de chevauchement.
 Figure 1.1
Figure 1.1
Dans la figure suivante, nous présentons une autre image scannée; Ce document scanné fait partie de la collection de documents saisis lors de l’opération Bouclier défensif reliant Arafat au terrorisme (http: //www.mfa.gov.il– disponible le 7 octobre 2006). Ce document est significativement plus complexe que celui illustré à la figure précédente.
- Ici, le texte est présenté en plusieurs langues en utilisant plusieurs scripts – indiqués par les carrés pleins.
- Un logo est présent-esquissé, encore une fois, par un ovale en pointillé.
- Il y a aussi du texte écrit à la main, dont une partie est une signature, et une partie est adjacente à un texte écrit de type ovale.
- Une table est présente et certaines des notes manuscrites sont au-dessus de la structure de la table.
- Pour compliquer davantage le traitement, l’image elle-même est quelque peu déformée, ce qui rend le traitement et la recherche de cette image encore plus compliqués que la recherche de l’image présentée à la figure précédente.

Figure 1.2
Pour rechercher ces documents et d’autres documents «réels» complexes, nous avons développé un prototype de CDIP dont l’architecture est illustrée sur la figure suivante (Argamon et al., 2006).
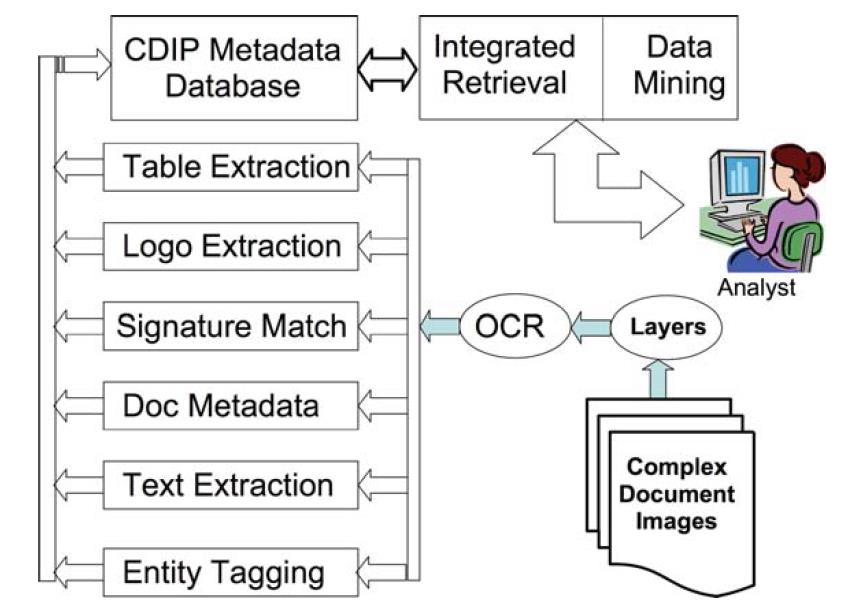
Initialement, les documents complexes sont introduits dans le système en tant qu’entrée, et de manière pipeline, sont traités par le logiciel d’extraction de couche, une solution ponctuelle. Ce logiciel extrait chaque type de composant, en supprimant les artefacts environnants. Par exemple, les tables, les signatures, le texte, etc. sont séparés les uns des autres. Des composants individuels sont envoyés au module de reconnaissance de caractères optiques afin de reconnaître et de corriger les parties de texte de l’artefact.
Notez que les types de composants autres que le texte pur auront du texte en tant que partie d’eux; par conséquent, ils doivent également être traités par le logiciel OCR, une solution ponctuelle. Notre implémentation actuelle utilise le moteur ABBYY FineReader Engine; par conséquent, de nombreuses langues sont déjà prises en charge. Cependant, ni l’arabe ni le script farsi ne sont parmi eux. À l’avenir, nous prévoyons d’ajouter un module OCR pour ces jeux de caractères non pris en charge et d’autres. Après avoir été traités par l’unité OCR, les composants sont envoyés aux solutions de points supplémentaires appropriés pour un traitement ultérieur. Par exemple, une partie du texte peut être envoyée à la solution de point de marquage d’entité pour l’identification du nom. Une signature peut être envoyée à la solution de point de correspondance de signature pour identification à partir d’un ensemble sélectionné de candidats possibles.
Indépendamment des solutions ponctuelles auxquelles un artefact est trouvé, chaque solution ponctuelle, y compris les modules de superposition et d’OCR, génère des métadonnées, c’est-à-dire des données sur les données décrivant le contenu des artefacts et stockant ces métadonnées dans la base de métadonnées.
Ce processus se poursuit pour tous les documents de la collection.
Finalement, les métadonnées sont recherchées ou extraites pour le contenu en conjonction avec une recherche de texte traditionnelle des composants textuels.
Puisque les métadonnées sont générées pour chaque type de composant dans un document par leur solution ponctuelle correspondante et qu’elles sont toutes stockées dans les mêmes métadonnées associées au même document (identificateur), elles peuvent être interrogées et extraites pour le contenu d’une manière uniforme et cohérente.
Ainsi, on peut interroger sur des informations composites qui ne sont incluses dans aucun type de composant individuel mais qui sont présentes lorsque plusieurs types de composants sont visualisés dans l’agrégat et que des corrélations possibles sont révélées.
En utilisant notre prototype de fonctionnalité limitée, nous avons déjà trouvé des documents qui n’auraient pas été identifiés comme pertinents.
Par exemple, dans un cas, nous recherchions des documents d’une certaine organisation sur un sujet particulier. Notre prototype a trouvé non seulement les documents où le nom de l’organisation et le sujet étaient présents dans le composant texte, mais aussi les documents dont la source (nom de l’organisation) n’était mentionnée nulle part ailleurs que dans leur logo.
Ces derniers documents n’auraient pas été trouvés à l’aide de solutions ponctuelles conventionnelles étant donné qu’une solution de traitement de texte n’identifierait pas la source et qu’une solution de correspondance de logo n’identifierait pas le sujet. Nos activités actuelles impliquent l’incorporation d’une plus grande variété de solutions ponctuelles, le développement d’une meilleure approche de la fusion des métadonnées, et l’évaluation et l’amélioration de la précision de la récupération du prototype.
Établissement d’un référentiel de documents complexes
Les évaluations de systèmes sont généralement effectuées au moyen d’un point de référence. Dans le domaine du système de recherche, depuis 1992, l’Institut national des normes et de la technologie (NIST) organise un forum d’évaluation annuel appelé TREC (voir trec.nist.gov) où les chercheurs reçoivent des données de référence et des requêtes sur leurs systèmes respectifs. . Les résultats des différents essais effectués par les systèmes individuels sont soumis aux organisateurs du TREC pour évaluation.
À la mi-novembre, les résultats de l’évaluation sont rendus publics.
Les problèmes liés à l’utilisation des données TREC et des requêtes pour évaluer un prototype de CDIP sont que toutes les données de piste sont « maniables par ordinateur » et sont de nature textuelle; c’est-à-dire qu’ils ne sont pas du «monde réel». Il n’existait donc pas de collection de référence pour l’évaluation du CDIP.
En vue de l’établissement d’un point de référence du CDIP, plusieurs caractéristiques de collecte ont été sélectionnées pour maintenir la longévité de l’applicabilité de l’ensemble de collecte et de recherche développé. Ceux-ci incluent que la collection:
- couvre une richesse d’entrées en termes de formats, de longueurs, de genres et de variations dans la qualité d’impression et d’image.
- inclut des documents qui contiennent du texte manuscrit et des notations, des polices diverses, des jeux de caractères multiples et des éléments graphiques, à savoir des graphiques, des tableaux, des photos, des logos et des diagrammes.
- contienne un volume de documents suffisamment important.
- contienne des documents dans plusieurs langues, y compris des documents qui ont plusieurs langues dans le même document.
- contenne un vaste volume de documents redondants et non pertinents.
- soit compatible avec diverses applications, ce qui inclut des communications privées au sein des groupes et entre ceux-ci, en planifiant des activités et en déployant des ressources.
- être publiquement disponible à un coût minimal et sous licence.
Après une étude minutieuse de plusieurs sources potentielles, une collection de documents a été sélectionnée, un large éventail de requêtes simples et complexes a été développé et les documents pertinents correspondants ont été déterminés. Une description complète est fournie dans Lewis et al. (2006). En bref, la collection choisie est un sous-ensemble des documents de l’accord de règlement principal hébergé par l’Université de Californie à San Francisco en tant que Legacy Tobacco Document Library (voir http://legacy.library.ucsf.edu). Ces données ont été rendues publiques par le biais de procédures judiciaires contre les industries du tabac et les instituts de recherche américains.
Pour la plupart, les documents sont distribués gratuitement et sont libres de droits d’auteur. (Les parties poursuivies ne possédaient pas certains des documents de la Legacy Tobacco Document Library, par conséquent, certaines d’entre elles sont potentiellement soumises à des restrictions de copyright.)
La collection comprend environ 7 millions de documents ou environ 42 millions de pages numérisées en TIFF (environ 1,5 TB). Ces documents sont principalement en anglais; cependant, il existe des documents en allemand, français, japonais et quelques autres langues. Certains de ces documents incluent également plusieurs langues dans un document donné.
Lorque de multiples entreprises sur plusieurs sites utilisant une diversité de scanners ont scannées les pages, la qualité d’image résultante varie considérablement.
Dans l’accès de 50 requêtes sont disponibles jusqu’à présent, la portée et la taille de jeu de résultats varie considérablement. Pour une discussion complète sur le prototype CDIP et la collection de référence, voir Agam et al. (2006).
Un « stemming arabe»
L’anglais n’est évidemment pas la seule langue dans laquelle existent des documents complexes
Comme le montre la figure 1.2 par exemple, les documents complexes comprennent parfois plusieurs langues sur une seule page. De plus, pour les applications antiterroristes, la plupart des documents complexes d’intérêt ne sont généralement pas en anglais. Nous décrivons maintenant une future « solution ponctuelle » CDIP potentielle, un stemmer arabe léger développé au IIT IR Lab.
La racinisation (stemmer en anglais) légère développée (voir Fig. 1.4, avec l’aimable autorisation d’Aljlayl et Frieder (2002)) consiste en une série de règles dérivées basées sur la structure grammaticale de la langue arabe. Ces règles localisent et suppriment les préfixes et les suffixes les plus fréquents. Comme indiqué dans Aljlayl et Frieder (2002):
« Tous les mots arabes sont basés sur des racines tri-littérales ou quadri-littérales. Ainsi, choisir 3 lettres comme racine minimale préserve l’intégrité du sens du mot. Réduire le mot à moins de 3 lettres entraîne la perte d’au moins une des lettres originales. Dans chaque étape, si un affixe est apparié à un mot, alors la condition que la racine soit supérieure ou égale à 3 caractères attachés à cette action est testée sur ce qui serait la partie résultante, si cet affixe était enlevé.
Une fois qu’un affixe est apparié dans un mot et que les caractères restants satisfont la condition, alors cet affixe est supprimé et le contrôle passe à l’étape suivante; si la règle n’est pas acceptée, l’affixe suivant est testé jusqu’à ce qu’une règle de cette étape se déclenche et que le contrôle passe à l’étape suivante ou qu’il n’y ait plus d’affixes satisfaisant les règles de cette étape, donc le contrôle passe à l’étape suivante.»
Le stemming n’est clairement pas un but final; c’est plutôt un moyen vers un but.
Notre objectif était la recherche précise de documents en arabe. Ainsi, pour évaluer l’impact de notre stemmer, nous avons comparé la précision de recherche soutenue contre le non-stemming (recherche basée sur le mot), en utilisant l’état de l’art de « stemmer », et notre approche.
Les gains de performance observés étaient statistiquement significatifs au niveau de 99% pour notre approche par rapport à l’approche basée sur les mots, et au moins au niveau de 95% pour notre approche par rapport à l’état de l’art.
De plus, nous avons observé une amélioration de plus de 70% de la précision dérivée de notre approche par rapport aux approches de recherche conventionnelles basées sur les mots et une amélioration de 20% par rapport aux approches basées sur l’état de l’art.
Pour plus de détails sur le stemmer arabe, voir Aljlayl et Frieder (2002). Une version optimisée (en termes d’efficacité) du stemmer arabe décrit ci-dessus a été autorisée par IIT à Blue Shoe Technologies. Pour d’autres efforts d’IIT IR Lab Arabic, voir Aljlayl et al. (2002) et Aqeel et al. (2006).